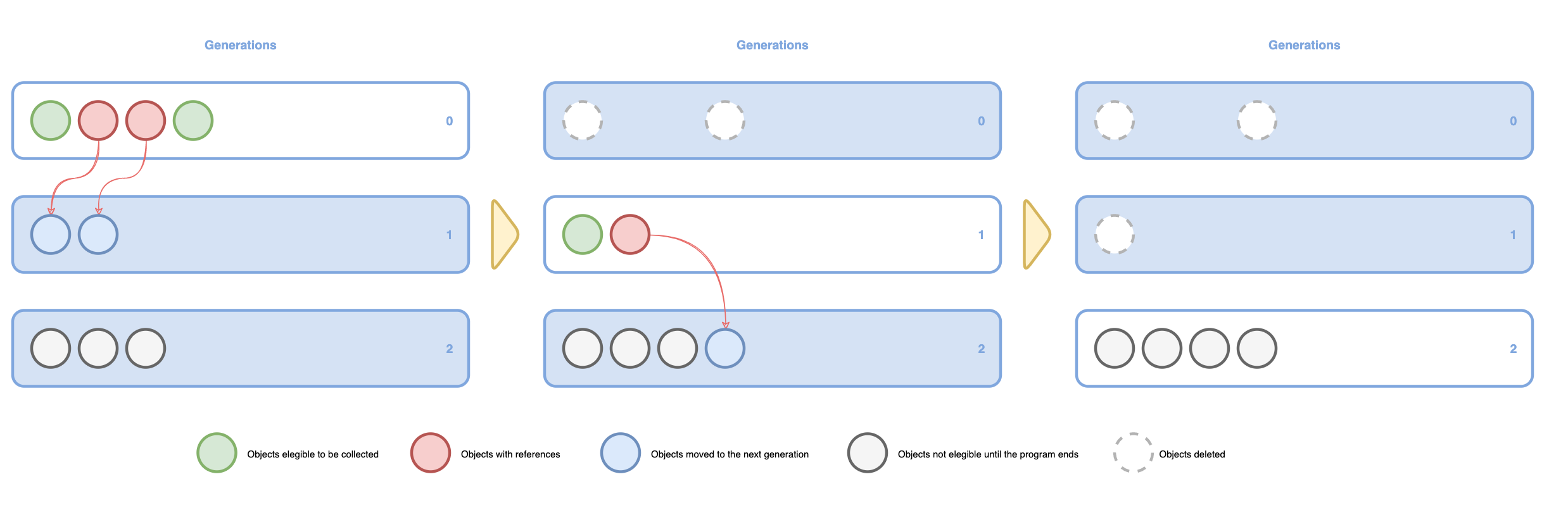
A guide to solve Unicode issues when using i18n with Django. Use your special characters when translating to Spanish, German or Chinese.
Read More
A guide to solve Unicode issues when using i18n with Django. Use your special characters when translating to Spanish, German or Chinese.